- 빌드 과정
컴파일 전체 흐름
전처리기 > 컴파일러 > 어셈블러 > 링커
- 전처리기 : 주석삭제, 코드치환(include).
- 컴파일러 : (헤더는 컴파일 주체가 아님, cpp파일을 컴파일 하는 데 헤더 내용이 포함되게 됨)
우리 눈에 보기에는 같은 이름인덴 같은 이름이 아닌 애들(오버로딩) 처리.
중간 파일 .obj 파일 만들기 -> 실행 메모리 크기 결정됨. - 어셈블러 : 진짜 기계어 코드로 변경.
- 링커 : 각 .obj파일에서 기계어로 번역된 것을 모두 하나로 모음. => 결과물 .exe파일
네임맹글링(name mangling)
컴퓨터가 더 이해하기 쉽게 바꿔서 컴파일러로부터 링커로 넘기는 것
- 메모리 위치


프로그램이 실행되기 위해서는 운영체제(OS)가 프로그램의 정보를 메모리에 로드 해야 한다.
또한 프로그램이 실행되는 동안 CPU가 코드를 처리하기 위해서는, 메모리가 명령어와 데이터들을 저장해야 한다.
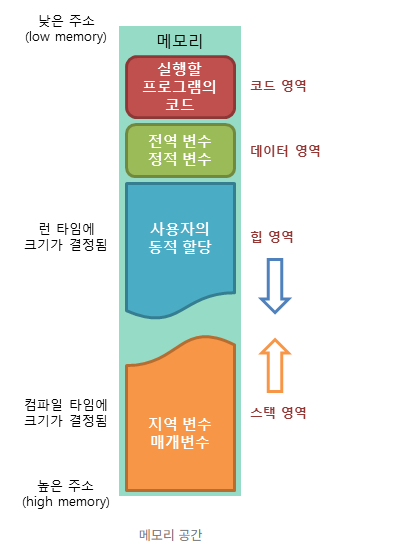
코드 영역
- 상수, 자료형, 클래스
- 실행할 프로그램의 코드가 저장되는 영역
- 프로그램이 시작하고 종료될 때 까지 메모리에 계속 남아있는다.
데이터 영역
- 전역 변수, static
- 프로그램의 시작과 함께 할당되며 프로그램 종료되면 소멸
힙 영역
- 프로그래머가 직접 공간을 할당, 해제하는 메모리 공간이다.
- 동적 할당은 힙이라고 하는 메모리를 사용하는 문법
-> 메모리의 크기는 운영체제가 관리해 주지만, 거의 램 크기만큼 할당할 수 있다.
new 연산자는 자료형의 포인터를 반환한다.
delete로 동적 할당한 메모리를 삭제할 수 있다.
delete
(1) 이 함수를 사용하지 못하게 하기위한 역할 -> 디폴트 복사 생성자(깊은 복사)와 디폴트 대입 연산자(얕은 복사)를 무의식적으로 사용할 수 있기에 사용 (스스로 감지하고 눈치채야하기 때문에 사용)
스택 영역
- 지역 변수
- 프로그램이 자동으로 사용하는 임시 메모리 영역
- 함수 호출 시 생성되는 지역 변수와 매개 변수가 저장되는 영역이고, 함수 호출이 완료되면 사라진다.
-> 이때 스택 영역에 저장되는 함수의 호출 정보를 스택 프레임(stack frame) 이라고 한다.
- 스택과 힙의 기본 개념 -> 메모리 차이
스택은 정적 메모리 할당에 사용되며, 컴파일 시간에 크기가 결정됩니다. 함수 호출과 함께 로컬 변수가 저장되는 곳으로, 함수가 종료되면 할당된 메모리가 자동으로 해제됩니다.
반면, 힙은 동적 메모리 할당에 사용되며, 프로그램 실행 중에 메모리 크기가 결정됩니다. 힙에 할당된 메모리는 개발자가 직접 관리해야 하며, 사용이 끝난 메모리는 명시적으로 해제해야 합니다.
- 정적 바인드, 동적 바인드
1. 정적 바인드
메모리를 할당할 때 이미 정해진 크기대로밖에 만들수 없고 수정이 불가능한 메모리 사용방식을 정적 바인딩이라고 한다. 예시) 변수
- 정적 바인딩은 절대로 플레이 중간에 메모리의 크기를 수정할 수 없다.
- 보통 스택과 데이터 영역에 바인딩
2. 동적 바인드 (동적 할당, 가상함수)
실행 이후에 값이 확정되면 동적 바인딩이라고 한다.
런타임에 호출될 함수가 결정되는 것으로, virtual 키워드를 통해 동적 바인딩하는 함수를 가상 함수라고 한다.
함수가 가상 함수로 선언이 되면, 포인터 변수가 실제로 가리키는 객체에 따라 호출의 대상이 결정된다.
(1) 동적할당은 힙이라고 하는 메모리를 사용하는 문법이고.
(2) 메모리의 크기는 운영체제가 관리해 주지만 거의 램크기만큼 할당할 수 있다.
오버 플로우

- 한정된 메모리 공간이 부족하여 메모리 안에 있는 데이터가 넘쳐 흐르는 현상이다.
- 오버 플로우의 종류 중에 힙 오버 플로우와 스택 오버 플로우가 있다.
- 힙은 메모리 위쪽 주소부터 할당되고, 스택은 메모리 아래쪽 주소부터 할당되기 때문에 각 영역이 상대 공간을 침범하는 일이 발생할 수 있다.
-> 이때 힙이 스택을 침범하는 경우를 힙 오버 플로우라 하고, 스택이 힙을 침범하는 경우를 스택 오버 플로우라고 한다.
메모리상으로 크기가 0인 데이터는 존재하면 안된다. -> 이유 ?
모순 발생 주소나, 배열에 값을 넣는데 그 크기가 0이면 코드적 모순이 생긴다.
주소 계산
ex)
100번지 ->
int arr[100];
int a=1;
100 번지 + a = 100 번지 + (자료형 크기) *1
- 바이트 패딩
바이트 패딩은 메모리 정렬법이다.
바이트 패딩 규칙
- 전 멤버변수 중에 가장 큰 바이트를 가진 기본자료형을 찾는다.
- 어떤 바이트의 변수가 나오든지 그 가장 큰 바이트로 할당한다.
- 그 다음 바이트가 2, 4 혹은 8바이트 안에 함께 들어갈 수 있는 변수라면 그 뒤로 채운다.
(다시 그 안에서 가장 큰 바이트로 채운다.) - 1번으로 돌아간다.
(1)
class A -> 1바이트
{
};
(2)
class B -> 1바이트
{
public:
// 함수는 클래스의 크기에 영향을 주지 않는다.
// 맴버함수가 어떻게 해석되는지는 곧 알게 될거고.
void Function()
{
}
};
(3)
class C -> 1바이트
{
public:
// 비어있는 클래스의 크기가 1이라고
// 거기에 더해지는게 아니다.
bool Test;
};
(4)
class D
{
public:
bool Test; // 4
int Test0; // 4
};
Test(1) 가상(1) 가상(1) 가상(1) Test0(4) -> 8바이트
(5)
class E
{
public:
bool Test0; // 1
// Temp; // 1
// Temp; // 1
// Temp; // 1
int Test1; // 4
bool Test2; // 1
// Temp; // 1
// Temp; // 1
// Temp; // 1
};
Test0(1) 가상(1) 가상(1) 가상(1) Test1(4) Test2(1) 가상(1) 가상(1) 가상(1) -> 12바이트
(6)
class F
{
public:
bool Test0; // 1
bool Test1; // 1
// Temp; // 1
// Temp; // 1
int Test2; // 4
};
Test0(1) Test1(1) 가상(1) 가상(1) Test2(4) -> 8바이트
(7)
class J
{
public:
bool Test0;
int Test1;
__int64 Test2;
// 가장 큰 바이트를 찾는다 => 8
};
Test0(1) 가상(1) 가상(1) 가상(1) Test1(4) Test2(8) -> 16바이트
비어 있는 클래스 크기가 왜 1바이트 인가?
메모리상으로 크기가 0인 데이터는 존재하면 안된다. ->
이유 ?
모순 발생 주소나, 배열에 값을 넣는데 그 크기가 0이면 코드적 모순이 생긴다.
릭 확인 부분
Leck란 new를 하고 delet를 하지 않은 메모리를 말한다.
C++ 프로그래밍에 심각한 문제를 발생시킬 수 있으므로 릭은 무조건 잡아야한다.
'C++ 개념 정리' 카테고리의 다른 글
| 6. 생성자, 소멸자 (0) | 2026.01.03 |
|---|---|
| 5. 연산자 (0) | 2026.01.03 |
| 3. C++ template (0) | 2025.12.30 |
| 2. 추상 클래스 (0) | 2025.12.30 |
| 1. 객체 지향 프로그래밍 (Object-Oriented Programming, OOP) (0) | 2025.12.30 |